开云(中国)开云kaiyun·官方网站结束了推理才调的跨任务泛化-k体育平台app官方人口

对于DeepSeek,面壁智能首创东说念主刘知远最新发声!
开始:中国基金报
【导读】面壁智能集聚首创东说念主、首席科学家刘知远称,DeepSeek -R1让AI界迎来近似于2023年头的ChatGPT时刻
记者 尹振茂
2025年1月底以来,DeepSeek在国表里捏续火爆,受到业表里等闲照料。
日前,中国基金报记者专访面壁智能首创东说念主、首席科学家刘知远,请其驻防阐释DeepSeek火爆出圈的原因。

在刘知瞭望来,OpenAI o1特别于引爆了一颗原枪弹,但莫得告诉公共秘方。DeepSeek则可能是全球首个能够通过纯正的强化学习时间复现OpenAI o1才调的团队,他们通过开源并发布相对驻防的先容,为行业发展作念出了紧要孝敬。
由于开源,DeepSeek -R1让全天下意志到深度想考的才调,特别于让系数这个词东说念主工智能界限迎来了近似于2023年头的ChatGPT时刻。公共感受到大模子的才调又往前迈进了一大步。
刘知远指出,东说念主工智能大模子界限存在一个大模子密度定律,即模子才调密度随时刻呈指数级增强。2023年以来,大模子的才调密度约莫每100天翻一倍,即每过100天,咱们只需要一半的算力和一半的参数就能结束沟通的才调。
刘知远称,咱们行将迎来兴趣兴趣深刻的智能立异,它的高涨行将到来,这是可望且可及的。
以下是这次专访的全文。
中国基金报:近期DeepSeek在国表里受到等闲照料,请驻防谈谈主要原因是什么?
刘知远:这主如若因为DeepSeek最近发布的R1模子具有特别紧要的价值。这种价值主要体当今其能够复现OpenAI o1的深度推理才调。
因为OpenAI o1自己并莫得提供对于其结束细节的任何信息,OpenAI o1 特别于引爆了一颗原枪弹,但莫得告诉公共秘方。而咱们需要从新驱动,我方去寻找若何复现这种才调的身手。DeepSeek可能是全球首个能够通过纯正的强化学习时间复现OpenAI o1才调的团队,何况他们通过开源并发布相对驻防的先容,为行业发展作念出了紧要孝敬。
DeepSeek -R1的系数这个词老练进程,有两个特别紧要的亮点或价值。
源流,DeepSeek R1创造性地基于DeepSeek V3基座模子,通过大限制强化学习时间,得到了一个纯正通过强化学习增强的强推理模子,即DeepSeek-R1-Zero。这具有特别紧要的价值。因为,在历史上简直莫得团队能够到手地坚毅化学习时间很好地诓骗于大限制模子上,并结束大限制老练。
DeepSeek R1的第二个紧要孝敬,在于其强化学习时间不仅局限于数学、算法代码等容易提供奖励信号的界限,还能创造性地坚毅化学习带来的强推理才调泛化到其他界限。这亦然用户在本色使用DeepSeek- R1进行写稿等任务时,能够感受到其巨大的深度想考才调的原因。
综上,DeepSeek -R1的孝敬体当今两个方面:一是通过规定驱动的身手结束了大限制强化学习;二是通过深度推理SFT数据与通用SFT数据的搀和微调,结束了推理才调的跨任务泛化。这使得DeepSeek -R1能够到手复现OpenAI o1的推理水平。
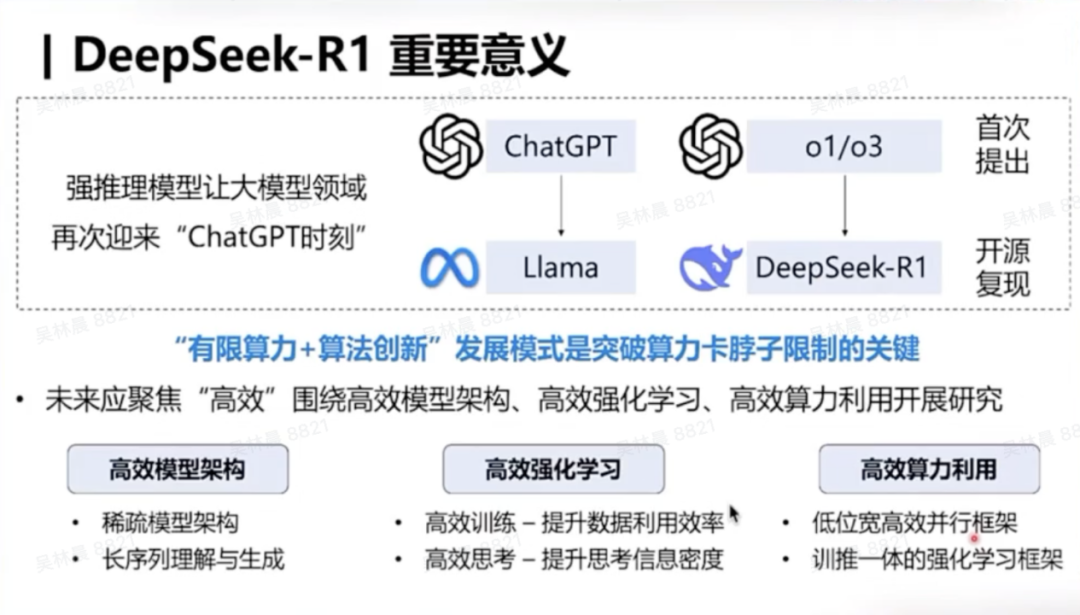
而且,由于开源,DeepSeek -R1让全天下意志到深度想考的威力。东说念主工智能界限迎来了近似于2023年头的ChatGPT时刻。每个东说念主感受到大模子的才调又往前迈进了一大步。
不外,咱们也需要合理评估DeepSeek -R1的兴趣兴趣。它在历史上更像是2023年Meta的LLaMA。
中国基金报:DeepSeek R1能够赢得全球性到手的原因有哪些?
刘知远:这与OpenAI弃取的某些计谋有特别大的关系。
OpenAI发布o1之后,源流弃取不开源;其次,它将o1深度想考的过程荫藏起来,第三,o1自己收费特别高。全球范围内仅有限的东说念主可通过o1感受到深度想考所带来的震荡。
而DeepSeek R1则像2023年头OpenAI的ChatGPT相同,让系数东说念主的确感受到了这种震荡,这是DeepSeek R1出圈的紧要原因。
如果咱们将DeepSeek发布的R1和之前的V3 联接起来探究,那么它的兴趣兴趣在于:在有限的算力资源相沿下,通过巨大的算法创新,遏制了算力瓶颈。它标明在有限的算力下,东说念主工智能公司也能作念出具有全球兴趣兴趣的逾越恶果。
这对中国AI的发展具有特别紧要的兴趣兴趣。
固然,咱们也应该看到,AI想要的确赋能全东说念主类,让每个东说念主皆能够用得上、用得起大模子和通用东说念主工智能,高效性是一个特别紧要的命题。这亦然DeepSeek- V3 和R1带给咱们的另一个紧要的启示。追求高效性是东说念主工智能发展内在的服务和需求。
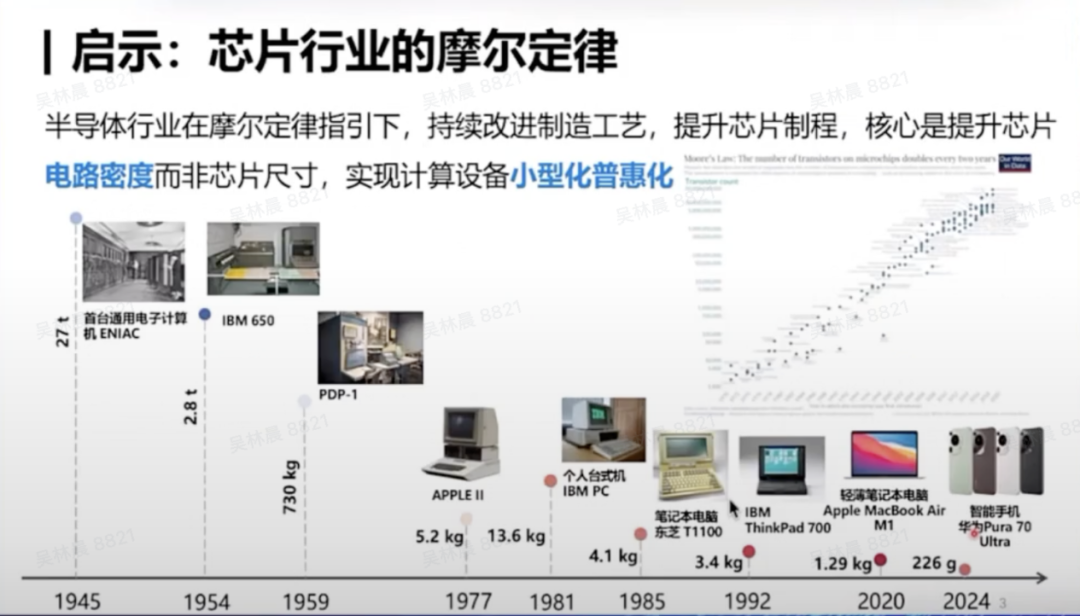
咱们看到,上一次的科技立异,即信息立异特别紧要的内核是筹算芯片的发展。
在畴昔的80年中,源流,一台筹算机需要一个房子才能装得下如今,每个东说念主手边皆有的手机、PC,以及各式筹算建立皆不错在特别小的建立上完成特别巨大的筹算才调。
这一切皆源于芯片行业在摩尔定律的指点下,不休鞭策芯片制程,素养芯片电路密度,从而结束筹算建立的袖珍化和普惠化,推动算力的普及。这是咱们追求高效性的内在需求。
2024年以来,咱们就突出强调要发展大模子的才调密度。
畴昔几年,咱们不错看到近似摩尔定律的风光,大模子的才调密度正随时刻呈指数级增强。2023年以来,大模子的才调密度约莫每100天翻一倍。也便是说,每过100天,咱们只需要一半的算力和一半的参数就能结束沟通的才调。
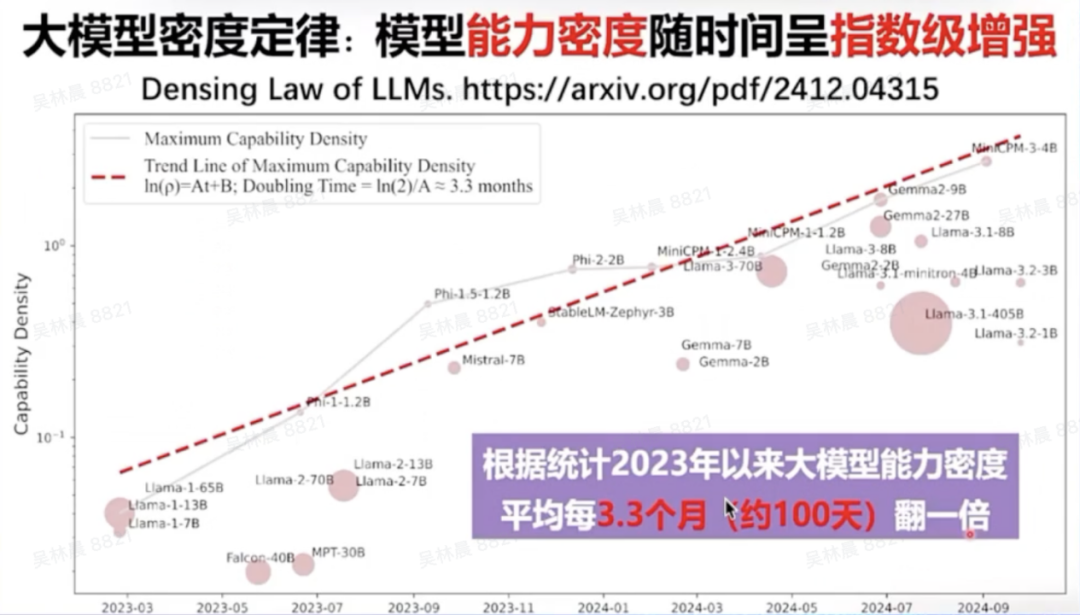
因此,面向将来,咱们应该不休追求更高的才调密度,勇猛以更低的老本——包括老练老本和筹算老本——结束大模子的高效发展。

因此,咱们觉得,智能立异赫然也要走过一个近似于信息立异的阶段,不休去提高才调密度、裁汰筹算老本。AI时期的中枢引擎,包括电力、算力以及大模子所代表的才调,这种密度定律应该亦然多数存在的。咱们需要不休通过高质地、可捏续的样式,去结束大模子的普惠,这是咱们将来的发展标的。
面向将来,咱们觉得,东说念主工智能有三大主战场,它们的筹画皆是让通用东说念主工智能达到顶尖水平。
源流,咱们要探索东说念主工智能的科学化时间决议,结束更科学、更高效的东说念主工智能结束样式。
其次,咱们要结束筹算系统的智能化,能够在筹算层面以更低的老本、更通用地将大模子诓骗于各个界限。
第三,咱们也要在各个界限探索东说念主工智能的广谱化诓骗。
终末, DeepSeek还让咱们看到,即使用小米加步枪,咱们也曾能够赢得紧要顺利。咱们行将迎来兴趣兴趣深刻的智能立异时期,它的高涨行将到来,这是可望且可及的。
中国基金报:DeepSeek-R1在这个时刻点出现并如斯出圈,是一种未必照旧具有某种势必性?
刘知远:它具有一定的势必性。
2024年,好多投资东说念主,甚而一些不从事东说念主工智能的东说念主皆问过我一个问题:中好意思东说念主工智能发展的差距是在变大照旧变小。
我其时示意,中国正在快速追逐,与好意思国起初进的时间之间的差距在迟缓减弱。尽管咱们仍濒临一些收尾,但这种追逐是不言而喻的。
2023年头,ChatGPT和后来GPT-4发布后,国内团队复现这两个版块的模子约略皆花了一年时刻。2023年底,国内团队复现了ChatGPT水平的模子才调;客岁四五月份,一线团队复现了GPT-4水平的才调。
但而后,像Sora、GPT-4o的模子,国内团队约略半年内就不错完成复现。这意味着,o1的模子才调,国内团队在半年傍边复现是可预期的。
DeepSeek的价值不仅在于能够复现,还在于能够更快、以更低老本、更高效地完成服务。从这个角度看,我觉得DeepSeek- R1当今出现存一定的势必性。
裁剪:格林]article_adlist_manual--> 校对:乔伊]article_adlist_manual--> 制作:舰长]article_adlist_manual--> 审核:木鱼]article_adlist_manual--> ]article_adlist-->
版权声明
]article_adlist-->
版权声明
《中国基金报》对本平台所刊载的原创内容享有著述权,未经授权辞谢转载,不然将根究法律背负。
授权转载和谐干系东说念主:于先生(电话:0755-82468670)
]article_adlist--> 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
背负裁剪:王若云 开云(中国)开云kaiyun·官方网站